Gepubliceerd in: Business Intelligence
Wat is een Datawarehouse?
Wat is een Datawarehouse?
Een datawarehouse kun je zien als een soort database waar je gestructureerde en semi-gestructureerde data op kunt slaan ten behoeve van business intelligence oplossingen. Je kunt het datawarehouse zien als een grote relationele database waar enorme hoeveelheden informatie kunnen worden opgeslagen en geanalyseerd worden die op kunnen lopen tot Petabytes.
In dit verband is het essentieel om het verschil te begrijpen tussen een datawarehouse en een relationele database, aangezien beide een cruciale rol spelen in het beheren van gegevens, maar met verschillende doelen en functionaliteiten.
- Wat is het verschil tussen een datawarehouse en een relationele database?
- Wat voor informatie kun je opslaan in een datawarehouse?
- Hoe wordt data opgeslagen in een datawarehouse?
- Waarom kiezen voor een Datawarehouse?
- Architectuur van een Datawarehouse
- Populaire Datawarehousing Systemen
- Wat kost een datawarehouse?
Wat is het verschil tussen een datawarehouse en een relationele database?
In zowel een datawarehouse als een relationele database wordt data opgeslagen in tabellen en kun je met gebruik van SQL-query’s informatie uit de database halen, aanpassen, toevoegen of verwijderen. Ook kun je in een datawarehouse met gebruik van DDL-statements tabellen maken, aanpassen en constraints toevoegen en kun je JOIN-operaties doen om data uit verschillende tabellen te relateren.
Een belangrijk verschil is echter dat de data die in het datawarehouse zit gehaald wordt uit de operationele van je organisatie en externe databases. Je gebruikt ze deze ook voor een ander doel.
Datawarehouse:
Doel: Het primaire doel van een datawarehouse is het ondersteunen van het nemen van strategische en analytische beslissingen. Het biedt een geconsolideerd overzicht van historische gegevens vanuit verschillende bronnen binnen een organisatie.
Focus: Datawarehouses zijn gericht op het analyseren van grote hoeveelheden gegevens om trends, patronen en zakelijke inzichten te ontdekken.
Relationele Database:
Doel: Een relationele database is ontworpen voor transactionele verwerking en dagelijkse operationele activiteiten. Het beheert gegevens efficiënt voor het uitvoeren van transacties, het bijwerken van records en het onderhouden van de operationele status van een organisatie.
Focus: Relationele databases richten zich op snelle gegevenstoegang, het uitvoeren van gestandaardiseerde zoekopdrachten en het handhaven van gegevensintegriteit.
Wat voor informatie kun je opslaan in een datawarehouse?
In een datawarehouse kun je gestructureerde en semi-gestructureerde data opslaan.
Gestructureerde data is data die op een of andere manier gecategoriseerd is. Dit wordt vervolgens in een soort relationele database opgeslagen in rijen met kolommen. Denk hierbij aan productgegevens, verkoopcijfers, meta data en afgeleide gegevens zoals gemiddeldes over een bepaalde tijd e.d.
Ongestructureerde data zijn bijvoorbeeld grote lappen tekst, afbeeldingen en video’s. De metadata over deze data is wel weer gestructureerd. Datawarehouses hebben niet de diepgang om deze data te analyseren (Unstructured Data | Snowflake Data Cloud Glossary, 2023)
Semi gestructureerde data hangt hier tussen in en kan op bepaalde manieren met wat moeite alsnog gestructureerd worden zoals bij XML, of JSON bestanden (Structured Data Versus Semi-Structured Data, n.d.).
Hoe wordt data opgeslagen in een datawarehouse?
Zowel in een datawarehouse als in een relationele database wordt informatie in tabellen opgeslagen er zijn echter verschillen in de diepgang van die tabellen.
- Relationele databases gebruiken platte twee dimensionale tabellen met rijen en kolommen om gegevens op te slaan. Ze zijn ontworpen om transactionele bewerkingen uit te voeren en zijn gestructureerd volgens de principes van normalisatie voor gegevensintegriteit.
- Gegevens in een datawarehouse worden vaak in meerdere dimensies opgeslagen en bevatten geneste gegevens als arrays.
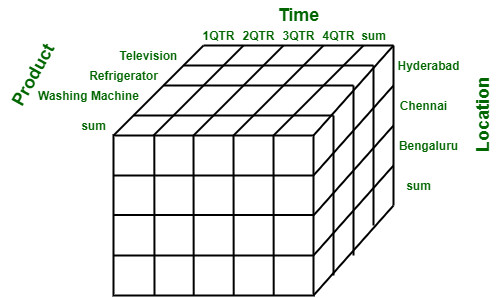
Afbeelding 1 Multidinensional Data Representation, (GeeksforGeeks, 2023)
Het grote verschil wat door de multi dimensionale dataopslag ontstaat is dat er in een tabel in een kolom op een rij een nested array van informatie staat. In een relatieve database zou dit opgeslagen moeten worden in meerdere tabellen die aan elkaar gerelateerd worden met verwijssleutels die met een join operatie samen worden gevoegd wat resulteert in herhalende groepen in de resultaattabel.
Data kan in de vorm van een record geplaats worden met key value pairs die tevens niet in alle rijen hetzelfde hoeven te zijn.
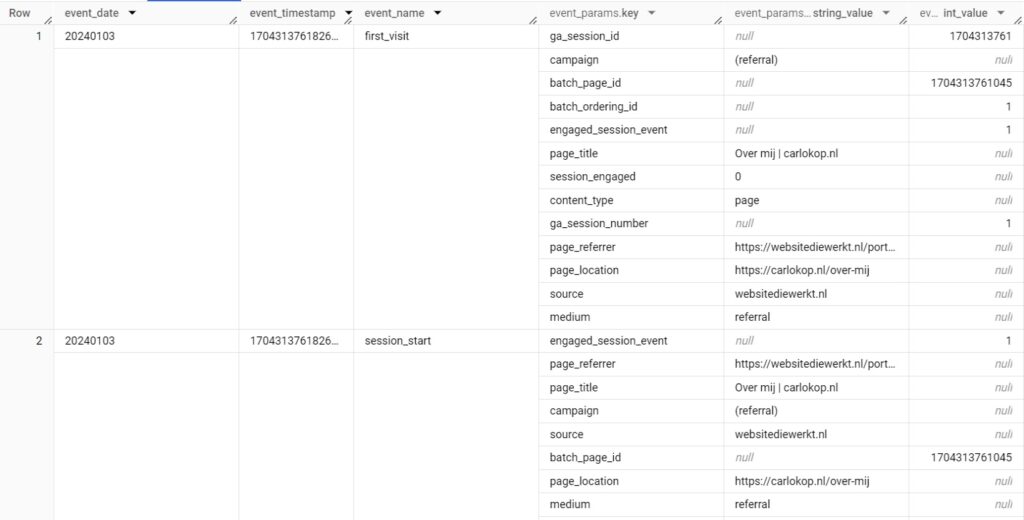
Afbeelding 2 Nested Google BigQuery GA4 data
Waarom kiezen voor een Datawarehouse?
Een datawarehouse kun je voor zowel kleine als grote big data projecten kiezen en hebben een verschillende doelen. Waar je echter rekening mee moet houden is dat data uit het systeem halen enige vaardigheden vereist die niet in alle organisaties voorhanden is en die data moet voldoende waarde toevoegen om concurrentievoordelen te behalen.
Uit diverse onderzoeken waaronder die van Troilio at all. (2017) blijkt dat het succes van big data projecten vooral komt door de kwaliteiten van het management om een cultuurverandering teweeg te brengen van een proces naar een data driven bussinessmodel en alleen dit implementeren om er af en toe wat analyses op uit te voeren zonder dat het echt zorgt voor een concurrentievoordeel zal niet het gewenste resultaat met zich meebrengen.
Het implementeren van een datawarehouse biedt diverse voordelen:
- Verbeterde Besluitvorming:
Door gegevens te centraliseren en een helder historisch perspectief te bieden, ondersteunt een datawarehouse weloverwogen besluitvorming op basis van nauwkeurige en actuele informatie. - Efficiënt Gegevensbeheer:
Een datawarehouse minimaliseert duplicatie en inconsistenties in gegevens, waardoor het beheer en de kwaliteit van gegevens aanzienlijk efficiënter worden. - Trendanalyse en Voorspellingen:
Het bijhouden van historische gegevens in een datawarehouse maakt gedegen trendanalyse mogelijk, wat leidt tot betere voorspellingen en strategische planning. - Snelle Rapportage:
Geavanceerde query- en rapportagemogelijkheden stellen gebruikers in staat snel toegang te krijgen tot informatie, wat cruciaal is voor real-time besluitvorming. - Schaalbaarheid:
Datawarehouses zijn ontworpen om flexibel en schaalbaar te zijn, waardoor ze moeiteloos kunnen meegroeien met de groeiende behoeften van een organisatie.
Architectuur van een Datawarehouse
De architectuur van een datawarehouse omvat essentiële componenten die gezamenlijk zorgen voor een robuuste gegevensinfrastructuur. Hieronder worden de belangrijkste aspecten verder toegelicht:
Extract, Transform, Load (ETL) Processen:
De ETL-processen vormen het fundament van gegevensintegratie. Deze procedures extraheren gegevens uit diverse bronnen, transformeren ze naar het gewenste formaat en laden ze vervolgens in het datawarehouse (GeeksforGeeks, 2023a). Hierdoor wordt niet alleen de uniformiteit van de gegevens gewaarborgd, maar ook de consistentie ervan.
Opslag:
Datawarehouses maken gebruik van geoptimaliseerde opslagstructuren, variërend van traditionele relationele databases tot moderne column-store databases. Deze geavanceerde opslagtechnieken zijn ontworpen om snelle toegang tot grote datasets te garanderen, waardoor complexe analyses efficiënt kunnen worden uitgevoerd.
Metadata:
Metadata speelt een centrale rol in het beheer van het datawarehouse. Het biedt gedetailleerd inzicht in de betekenis, herkomst en context van de opgeslagen gegevens. Door metadata effectief te beheren, kunnen organisaties de traceerbaarheid van gegevens vergroten en de kwaliteit ervan verbeteren.
Query en Analyse Tools:
Krachtige query- en analysehulpmiddelen vormen de brug tussen gebruikers en het datawarehouse. Deze tools vereenvoudigen de interactie door intuïtieve querymogelijkheden en geavanceerde analytische functies aan te bieden. Ze stellen gebruikers in staat om complexe vragen te stellen en snel waardevolle inzichten te verkrijgen.
Data Mart:
Een data mart, als subset van het datawarehouse, is gericht op specifieke bedrijfsafdelingen (Wat Is Een Datamart? | Oracle, n.d.). Het biedt een geoptimaliseerde verzameling van gegevens die relevant is voor de unieke behoeften van een bepaalde afdeling. Hierdoor kunnen teams gemakkelijk toegang krijgen tot specifieke informatie die cruciaal is voor hun taken en besluitvormingsprocessen.
De samenwerking van deze componenten creëert een dynamisch en goed georganiseerd gegevenslandschap binnen het datawarehouse, waardoor organisaties kunnen profiteren van geavanceerde analyses en weloverwogen besluitvorming.
Populaire Datawarehousing Systemen
Enkele veelgebruikte datawarehousing systemen in de industrie zijn:
- Amazon Redshift: Een cloudgebaseerd datawarehouse van Amazon Web Services (AWS) dat schaalbaarheid en snelle query-prestaties biedt.
- Snowflake: Een cloudgebaseerd datawarehouse dat bekend staat om zijn architectuur met meerdere lagen en uitstekende schaalbaarheid.
- Microsoft Azure Synapse Analytics: Voorheen bekend als SQL Data Warehouse, biedt dit platform krachtige analysemogelijkheden in de Azure-cloud.
- Google BigQuery: Een volledig beheerd, serverloos datawarehouse dat bekend staat om zijn snelheid en eenvoudige schaalbaarheid.
- Teradata: Een gevestigde speler in de datawarehousing-industrie, bekend om zijn krachtige en schaalbare oplossingen.
De keuze voor een specifiek datawarehousing systeem hangt af van de specifieke behoeften van een organisatie, zoals schaalbaarheid, prestaties, integratiemogelijkheden en budgettaire overwegingen
Wat kost een datawarehouse?
De kosten van een datawarehouse kunnen variëren en worden beïnvloed door verschillende factoren, afhankelijk van de specifieke behoeften en de gekozen architectuur van een organisatie. Hier zijn enkele belangrijke aspecten die de kosten van een datawarehouse bepalen:
- Type Datawarehouse:
- On-Premise: Als een organisatie ervoor kiest om het datawarehouse op locatie te onderhouden, zijn er initiële kosten verbonden aan de aanschaf van hardware, softwarelicenties en de installatie ervan. Daarnaast zijn er doorlopende kosten voor onderhoud, beheer en energieverbruik.
- Cloud-Based: Cloudgebaseerde datawarehouses, zoals die aangeboden worden door cloudserviceproviders (bijvoorbeeld AWS Redshift, Azure Synapse Analytics, Google BigQuery), werken op een pay-as-you-go-model. Organisaties betalen alleen voor het gebruik van resources en dan in het bijzonder voor de opslagcapaciteit en een bedrag voor de queries die gedaan worden. Het is goed om te benadrukken dat de kostenstructuur per provider kan verschillen, en het kan handig zijn om te wijzen op het belang van het vergelijken van de specifieke prijsmodellen van elke cloudserviceprovider.
- Opslag- en Rekenresources:
- De hoeveelheid gegevens die wordt opgeslagen en de mate van rekenkracht die nodig is voor analyses beïnvloeden de kosten. In de cloud wordt vaak betaald op basis van de gebruikte opslagruimte en de hoeveelheid verwerkte gegevens.
- Data-integratie en ETL Processen:
- Het implementeren van Extract, Transform, Load (ETL) processen voor gegevensintegratie brengt kosten met zich mee. Deze kosten omvatten het ontwikkelen en onderhouden van ETL-scripts, het extraheren van gegevens uit verschillende bronnen en het transformeren ervan om geschikt te zijn voor het datawarehouse.
- Query en Analyse Tools:
- Het gebruik van geavanceerde query- en analysehulpmiddelen kan extra kosten met zich meebrengen, afhankelijk van de licentiestructuur en het gebruikspatroon. Sommige platforms bieden mogelijkheden voor ad-hoc query’s, rapportage en datavisualisatie, maar deze functies kunnen gepaard gaan met licentiekosten.
- Onderhoud en Beheer:
- Doorlopende kosten zijn verbonden aan het onderhouden en beheren van het datawarehouse. Dit omvat het monitoren van prestaties, het waarborgen van gegevensintegriteit, het implementeren van beveiligingsmaatregelen en het uitvoeren van regelmatige updates.
- Training en Personeelskosten:
- Training van personeel voor het beheren en gebruiken van het datawarehouse brengt kosten met zich mee. Daarnaast kunnen personeelskosten toenemen naarmate het gebruik van het datawarehouse groeit, omdat meer personeel mogelijk nodig is voor onderhoud en ondersteuning.
- Schaalbaarheid en Uitbreiding:
- Het datawarehouse moet mogelijk worden geschaald om te voldoen aan groeiende gegevensvolumes en analytische eisen. Schaalbaarheidskosten zijn afhankelijk van de gekozen architectuur en kunnen bestaan uit het toevoegen van opslagcapaciteit, rekenkracht of extra services.
- Het datawarehouse moet mogelijk worden geschaald om te voldoen aan groeiende gegevensvolumes en analytische eisen. Schaalbaarheidskosten zijn afhankelijk van de gekozen architectuur en kunnen bestaan uit het toevoegen van opslagcapaciteit, rekenkracht of extra services.
De kosten van een datawarehouse worden beïnvloed door infrastructuur, operationele aspecten en effectieve data governance. Data governance is cruciaal voor naleving van normen en zorgt voor betrouwbaarheid. Belangrijke aspecten, zoals datakwaliteit, beveiliging, data levenscyclusbeheer en metadatabeheer, kunnen kosten met zich meebrengen. Het integreren van een solide data governance-framework draagt bij aan duurzaamheid en betrouwbaarheid. Een holistische benadering waarbij zowel infrastructuur als data governance worden overwogen, is essentieel voor efficiënt gegevensbeheer.
Met name gegevensopslag is een punt van aandacht. Als je alle historische data wilt bewaren zal de opslagcapaciteit altijd toe blijven nemen. Opslag van data wordt weliswaar steeds goedkoper maar het toenemen van opslagcapaciteit zal naar alle waarschijnlijkheid de kosten voor dataopslag veruit overstijgen.
Referenties:
GeeksforGeeks. (2023, April 25). MultiDimensional Data model. https://www.geeksforgeeks.org/multidimensional-data-model/
GeeksforGeeks. (2023a, February 2). ETL process in data warehouse. https://www.geeksforgeeks.org/etl-process-in-data-warehouse/
Structured Data versus Semi-Structured Data. (n.d.). Snowflake. https://www.snowflake.com/guides/structured-data-versus-semi-structured-data
Troilo, G., De Luca, L. M., & Guenzi, P. (2017). Linking Data‐Rich Environments with Service Innovation in Incumbent Firms: A Conceptual Framework and Research Propositions. Journal of Product Innovation Management, 34(5), 617–639. https://doi.org/10.1111/jpim.12395
Unstructured Data | Snowflake Data Cloud Glossary. (2023, October 16). Snowflake. https://www.snowflake.com/data-cloud-glossary/unstructured-data/
Wat is een datamart? | Oracle. (n.d.). https://www.oracle.com/nl/autonomous-database/what-is-data-mart/